Apache Kafka is an open-source stream-processing software created by LinkedIn and maintained by Confluent. Apache Kafka helps you to decouple data streams & systems to achieve a few goals:
Kafka is used as a transportation mechanism. Here are some common applications:
Messaging systems
Activity tracking
Gather metrics from different locations
Gather Logs
Stream processing
Decoupling of system dependencies
Netflix embraces Apache Kafka as the de-facto standard for its eventing, messaging, and stream processing needs. Kafka acts as a bridge for all point-to-point and Netflix Studio wide communications. It provides us with the high durability and linearly scalable, multi-tenant architecture required for operating systems at Netflix.
Basic Concepts
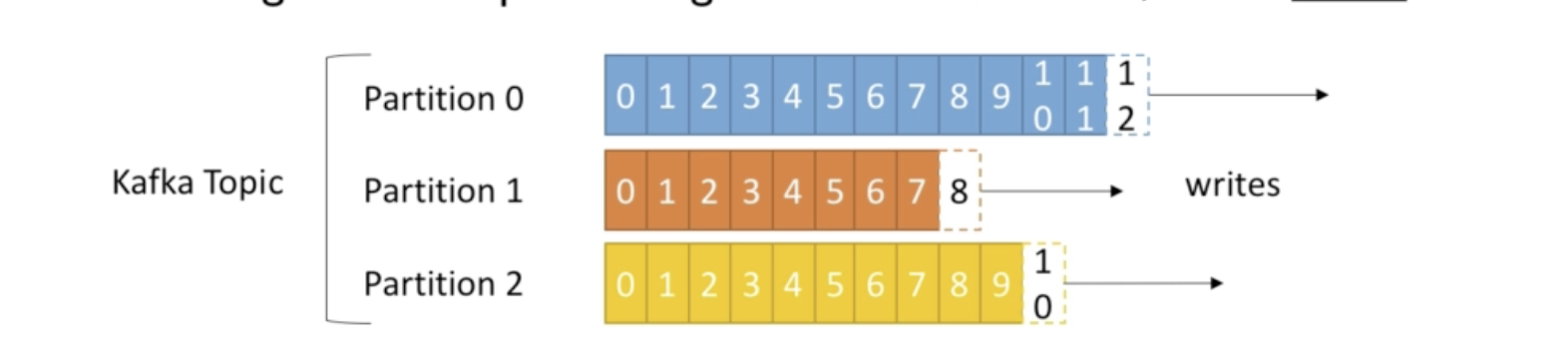
Topics:a particular stream of data (similar to a table in a database)
Topics are split in partitions
Each partition is ordered
Each message within a partition gets an incremental id, called offset
.
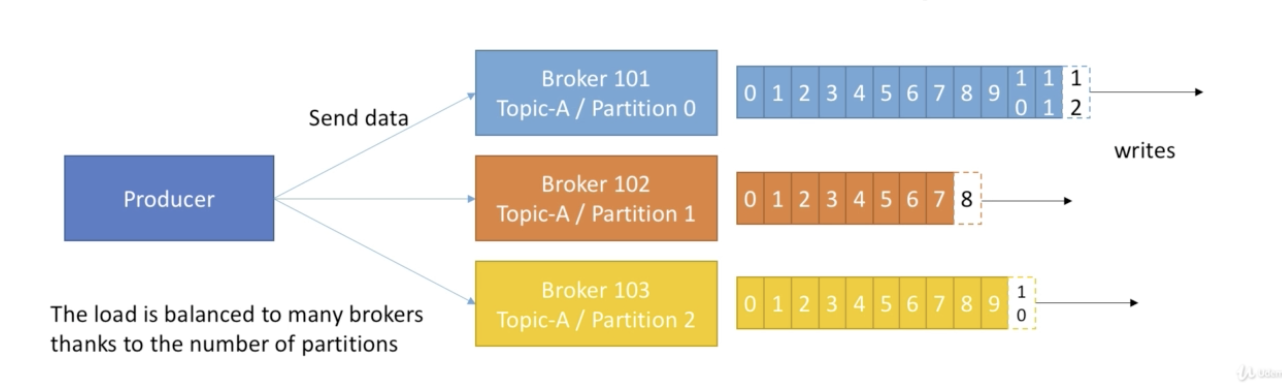
A Kafka Cluster is composed of multiple brokers (Servers)
Each broker is identified with its ID
Producers write data to topics
Producers automatically know which broker and partitions to write to
In case of Failures, the Producer will automatically recover
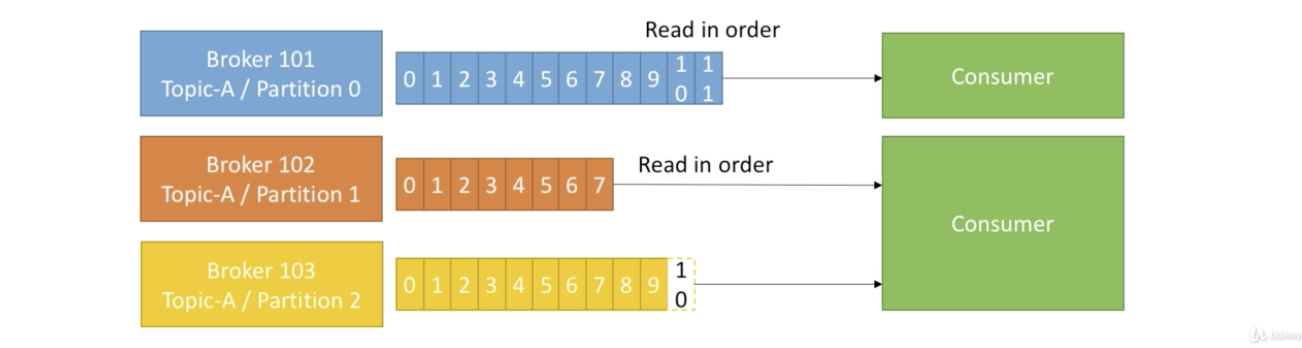
From the consumer side
Read data from a topic
Know which broker to read from
In case a broker failures, consumer know how to recover
Data is read in order within each partition
Kafka vs
Storm
Distributed real time processing
Stateless, Data is streamed
Stream abstraction
Micro batching processing
Kafka
It is a distributed message broker
It is about transferring messages, data is store in the filesystem